关于本网站
记录 PyTorch 编程和论文等内容。内容可以作为学习的参考和笔记,也是周报内容的补充。
基础
张量
张量(Tensor)是 PyTorch 操作的基本单位,创建方式多种多样:
# 直接从 list 创建
data = [[1, 2],[3, 4]]
x_data = torch.tensor(data)
# 从 numpy 数组创建
np_array = np.array(data)
x_np = torch.from_numpy(np_array)
# 从另一个张量创建
x_ones = torch.ones_like(x_data) # retains the properties of x_data
print(f"Ones Tensor: \n {x_ones} \n")
x_rand = torch.rand_like(x_data, dtype=torch.float) # overrides the datatype of x_data
print(f"Random Tensor: \n {x_rand} \n")
张量的参数
张量有3个基本参数,shape,dtype 和 device。
shape是张量的形状dtype是张量存储的数据类型device是张量存储的设备
张量操作与计算图
张量有多种多样的操作,许多操作可以在线性代数中找到原型,张量也可以看作是一种向量。操作函数手册
PyTorch 的张量操作分为原地操作(inplace)和非原地(out-of-place)操作,其中非原地操作会为结果分配一块新内存,返回一个新的张量。
x_data = [[1, 2, 3]]
x = torch.tensor(x_data)
# torch.Size([1, 3])
print(x.shape)
# squeeze 会移除张量的一个维度,返回一个新的向量
# 除了下面这种写法,也可以写成 x = torch.squeeze(x, 1)
x = x.squeeze(0)
# torch.Size([3])
print(x.shape)
而原地操作(比如 torch.add_())会直接修改张量的内存,这会破坏计算图(computational graph),PyTorch 无法追踪这样的修改。
首先,通过 torch.tensor 创建的张量,默认不会要求梯度追踪,也就不会被纳入计算图构建,因此需要指定 require_grad=True。
举例来说,以下代码计算了一个梯度:
import torch
x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True) # 注意需要 float 类型且设置梯度追踪
y = x ** 2
y0 = torch.tensor([1.0, 1.0, 1.0]) # 同样是 float
loss = 0.5 * (y - y0) ** 2
loss = loss.sum() # 把 loss 向量各个分量求和成一个标量,注意它依然是 Tensor,形状是 torch.Size([])
# 使用 backward 自动进行反向传播梯度计算
loss.backward()
# 此时 x.grad 存储的是 ∂(loss)/∂x
print(x.grad) # 输出梯度
能计算的原因是,PyTorch 从 x 开始追踪了一整条计算的链路,形成了计算图;最开始 x 创建时要求梯度追踪,随后 y 通过 x ** 2 创建,loss 通过 0.5 * (y - y0) ** 2 创建,都被纳入计算图中。当 loss 调用 backward() 方法时,PyTorch 会根据存储的计算图找到各个张量之间的关系,也是利用链式法则计算出 loss 对与之相关的所有张量的梯度,即
\[ \frac{\partial{loss}}{\partial{x}}=\frac{\partial{loss}}{\partial{y}}\frac{\partial{y}}{\partial{x}}=2(y-y_0)x \]
而如果计算图被破坏,则无法正常求解梯度:
import torch
x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True) # 注意需要 float 类型且设置梯度追踪
# 这里 item() 方法提取出了张量索引0处的标量数值,y 是通过这个数值创建的,y 和 x 已经没有关系了
y = torch.tensor([x[0].cpu().item(), x[0].cpu().item(), x[0].cpu().item()])
y0 = torch.tensor([1.0, 1.0, 1.0]) # 同样是 float
loss = 0.5 * (y - y0) ** 2
loss = loss.sum()
loss.backward()
# 此时 x.grad 存储的是 ∂(loss)/∂x
print(x.grad) # 输出梯度(None!)
因此,原地操作、从张量中取数值等操作要慎重,一般我是在最后全部一轮的训练流程计算完毕后通过 item() 方法拿到想要的张量中的数值存起来用于后期画图和信息输出等,此时这些张量已经不会继续参与运算了,下一个训练步,PyTorch 又会从零开始构建计算图。
注意 backward() 方法在计算出相关张量的 grad 后默认会清空计算图。
利用 x 中的某一个元素来构造 y 同时防止计算图断裂的办法如下
x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
y = x[0].repeat(3) # 或者 torch.stack([x[0], x[0], x[0]])
PID 参数整定公式参考
以 \(K_p\) 的更新为例,
\[ E=\frac{1}{2}(y-r)^2 \]
\[ \begin{align} \frac{\partial{E}}{\partial{K_p}}&=\frac{\partial{E}}{\partial{y}}\frac{\partial{y}}{\partial{(ku)}}\frac{\partial{(ku)}}{\partial{u}}\frac{\partial{u}}{\partial{K_p}} \\&=(y-r)sgn(n)K (r-y) \end{align} \]
\[ \Delta K_p=-\eta \frac{\partial{E}}{\partial{K_p}} \]
\[ K_p'=K_p+\Delta K_p \]
自适应控制
目前,根据有关资料我们写出了输出 \(K_p\)、\(K_i\) 和 \(K_d\) 3个参数的神经网络。推导公式中有一个项目 \(\frac{dy}{du}\) 为表征系统特性的量,它不是一个时不变常量。在实现时,我们采用符号函数估计的方式替代了这一个部分,形成了所有参与运算的部分均已知的梯度更新公式。这种办法的理论不完备之处在于对 \(\frac{dy}{du}\) 的估计,这个时变量实际可能会形成复杂的函数,在一些情况下可能无法简单地使用符号函数来近似。
在近期阅读的论文1中,注意到了之前没了解过的自适应控制2思路。论文的基本策略是通过 RBF 网络对被控对象进行在线的学习和辨识得到 \(\frac{dy}{du}\)。
原理
按照论文,做出的系统结构图如下,其中网络部分理论上可以以较小的成本换成任意 PyTorch 提供的现成函数或在此基础上构造的复合网络:
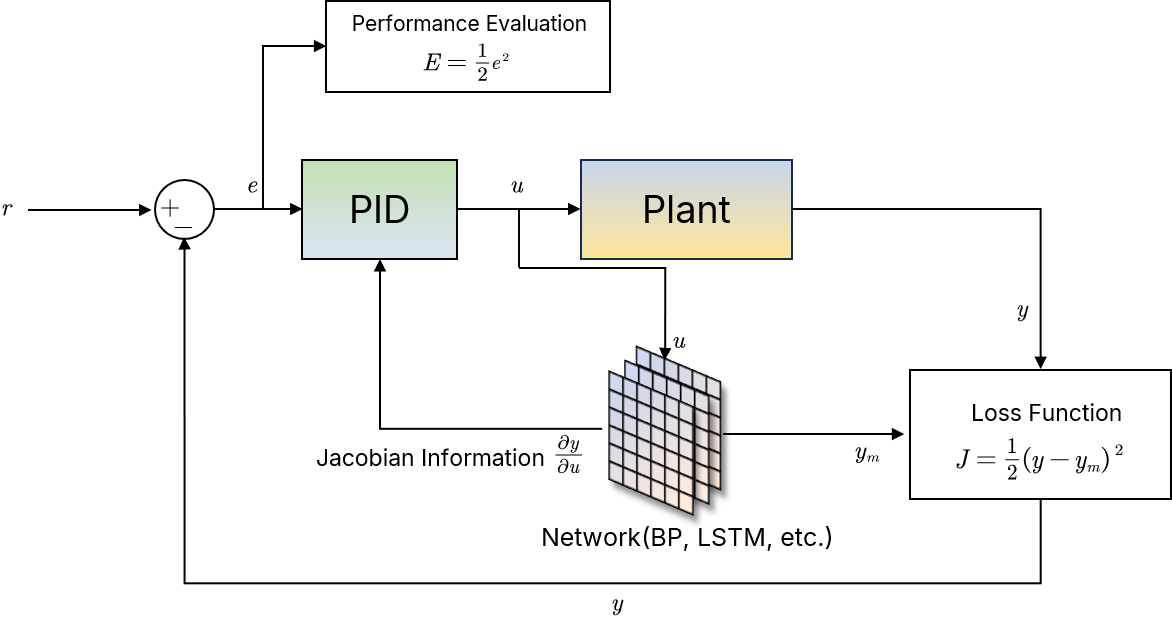
径向基网络是由径向基函数(Radical Basis Function,RBF)构成的,典型包含3层,第一层输入层,第二层隐藏层,第三层输出层。输入层到隐藏层会经过一个径向基函数(高斯核函数)实现非线性变换计算隐藏层输出:
\[
\begin{align}
h_j=exp(-\frac{||X-C_j||^2}{2b_j^2})
\end{align}
\]
上述过程中包含2个参数,一是每一个隐藏层神经元存储的“中心向量” \(C\),第 \(j\space (1\le j \le m) \) 个隐藏层神经元对输入 \(X\) 的每一个分量 \(x_i\space (1\le i \le n) \) 都存在一个中心值 \(c_{ij}\)。另一个是被一个隐藏层神经元存储的直径 \(b_j\)。
隐藏层到输出层的映射则是线性的,第 \(k\) 个时间步的神经网络输出是:
\[ \begin{align} y_m(k)=w_0+w_1h_1+w_2h_2+\dots+w_mh_m=\sum_{j=1}^{m}w_jh_j + w_0 \end{align} \]
\(w_0\) 是文中指定的超参数。上述网络可训练的参数包括隐藏层核函数的 \(C_j\) 和 \(b_j\) 以及输出层的权重 \(W\)。因为网络计算结构已知,所以可以通过手动推算的方式得到更新公式。
\(y_m\) 对应的是被控对象的输出,如上图所示文中使用的 Loss Function 用于评估神经网络辨识结果与被控对象输出的近似程度,随着训练的进行 loss 越小意味着网络对系统的辨识越准确,这样就有 \(\frac{dy}{du}\) 的估计公式
\[ \frac{\partial{y(k)}}{\partial{u(k)}}\approx\frac{\partial{y_m(k)}}{\partial{u(k)}} \]
随后定义针对控制器表现的评估函数 \(E=\frac{1}{2}(r-y)^2=\frac{1}{2}e^2\) ,这和目前我们做的工作的理论是一致的——在我们目前的理论中,更新 PID 参数依靠的就是函数 \(E\),需要解决 \(\frac{\partial{E}}{\partial{K_p}}\) 链式求导中出现的未知量 \(\frac{dy}{du}\),因为 \(K_p\) 等 PID 参数就是神经网络给出的,随即可以进一步得到 \(E\) 对神经网络参数的梯度,因为 \(E\) 与神经网络输出不存在直接的关系,因此在得到 \(E\) 对神经网络参数的梯度后必须手动对网络参数进行更新,是非常麻烦的。
而我注意到,在本文提出的策略中,用于评估神经网络表现的损失函数 \(J=\frac{1}{2}(y-y_m)^2\) 直接就是神经网络输出 \(y_m\) 的函数,因此从 PyTorch 角度看,张量计算图没有被破坏,可以利用 PyTorch 的自动梯度计算功能。 这也是之前说的可能会省事的理由,因为我们只要实现这样一个网络,就可以利用 PyTorch 自己的机制去更新网络权重,不需要手写网络参数更新逻辑。
而 PID 自己的参数更新还是按照链式法则来进行,以更新 \(K_p\) 为例,必要数据 \(\frac{\partial{E}}{\partial{K_p}}\) 的计算方式为:
\[ \frac{\partial{E}}{\partial{K_p}}=\frac{\partial{E}}{\partial{y}}\frac{\partial{y}}{\partial{u}}\frac{\partial{u}}{\partial{K_p}} \]
最后一个参数 \(\frac{\partial{u}}{\partial{K_p}}\) 就是 PID 控制器的比例因子。上述公式中3个量都是已知的,有了上述的结果后,\(K_p\) 的更新就是:
\[ \Delta K_p=-\eta\frac{\partial{E}}{\partial{K_p}} \]
其中 \(\eta\) 是变化率。
总结
上述方法的最大好处是,神经网络的部分不用手写参数更新逻辑了,正确性可以得到较好的保证。
此外,通过和目前的思路比较,也会发现:原先的思路到了 \(\frac{\partial{E}}{\partial{K_p}}\) 其实和这篇论文中提出的想法几乎完全一致(梯度下降的方法本身就是一种符合数学逻辑的、合理的参数更新方式),但是我们的思路因为将神经网络直接摆到了给出 PID 参数的位置上,PID 控制器的控制效果评价函数和神经网络的损失函数都依赖 \(E\),那么就要在不存在 PyTorch 计算图关系的情况下利用 \(E\) 来更新网络权重了。而即便神经网络不给 PID 参数,利用梯度下降的规律我们也可以知道,一旦计算得到 \(\frac{\partial{E}}{\partial{K_p}}\) 等参数,我们也可以利用数学原理去手写 PID 参数的更新逻辑,而神经网络得到了 \(\frac{\partial{y}}{\partial{u}}\) 的可靠估计值, PID 参数相关的从 \(E\) 开始的梯度链的可靠性也会比单纯符号函数的估计要好。
当然,可能也可以用两个神经网络,一个神经网络负责辨识,一个神经网络用于给出PID参数,不过这个工作量相对会比较大,加上现在给出PID参数的神经网络的搜索能力还存在一些问题,所以我觉得目前这只能算是后面的可行方向之一。
-
Zhang, Ming-guang, Xing-gui Wang, and Man-qiang Liu. "Adaptive PID control based on RBF neural network identification." 17th IEEE International Conference on Tools with Artificial Intelligence (ICTAI'05). IEEE, 2005. (link) ↩
-
自适应控制(Adaptive Control)是一种控制策略,用于自动调整控制器的参数以适应系统动态的变化,特别适用于被控对象特性不确定或随时间变化的情况。 ↩